I vividly remember last year having a light bulb moment when Jensen provided his definition of an AI agent. An AI agent is an AI that can perceive, plan, reason, and act. For some reason, it took me hearing it from Jensen in context to really get it. I attended multiple sessions at GTC this year on a family of open source models designed specifically for agentic development, which deepened my understanding of accelerated computing, what it means to put AI “at the edge”, how a generative model is trained, and what agentic development really is.
Approximating Human Agency
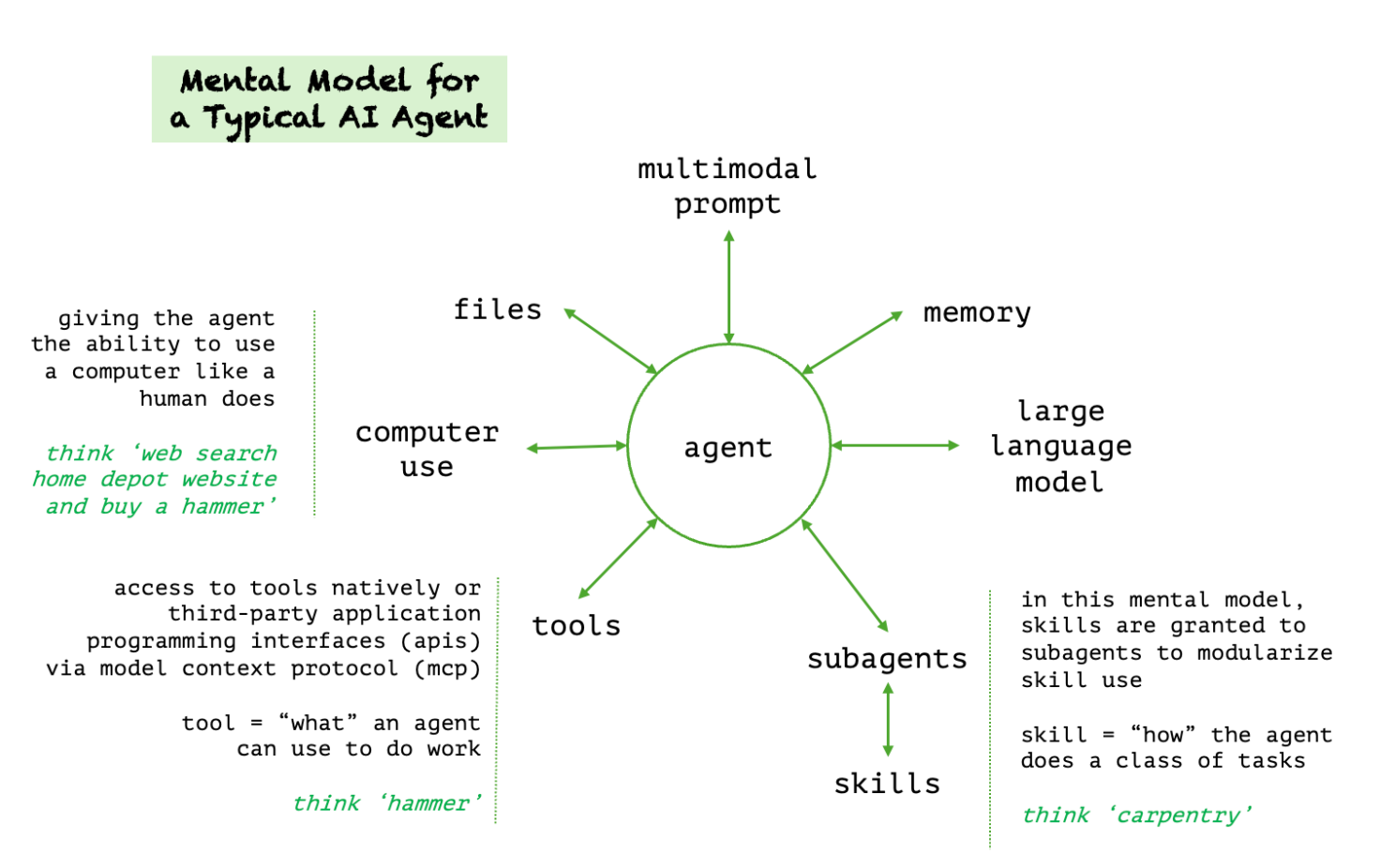
Perceive, plan, reason, and act. As humans, we do these things intuitively and without thinking. We just know how to do it. Our ability to perceive our environment relies on vision, hearing, our sense of touch, and our ability to translate this sensory information into meaning. Planning requires us to have executive functioning. This higher order mental ability allows us to make sense of data and organize it into a logical framework. As we reason through a problem, we consider alternatives and think back on prior experiences. And when we act, we intersect our inner world with the physical world. We use tools. We apply skills we have honed over time and based on our experience.
This intuitive set of human processes relies on multiple complicated systems. It takes a system of systems to make this possible. This is really the essence of agentic development – how to create a system of systems that proactively work together to meet our objectives without being explicitly told how.
Let's look at an example with a deep research agentic system. NVIDIA provides solution blueprints, models to implement, and packaged AI inference microservices. (They call these NIM – NVIDIA Inference Microservices). You may want to ask your vendor partners if they are using these blueprints, they really are a wealth of actionable information and tools. They also memorialize industry best practices.
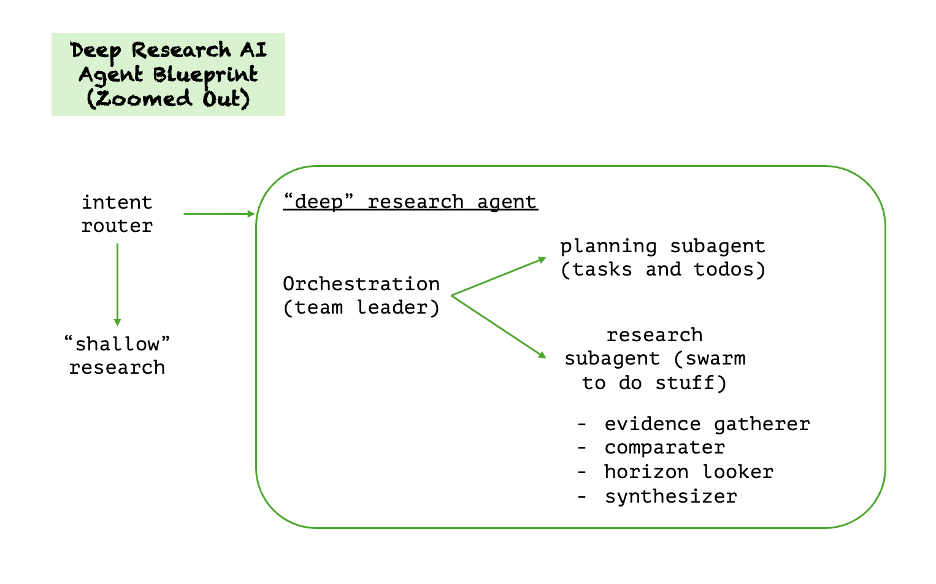
To put this in context, thank about a set of helpdesk deep research agents in a call center. There could be an intake agent, a triage agent, an escalation agent, and a prior cases agent. All of these are deep research agents. These four agents would each be designed with skills and tools. They are small and contained to maximize their effectiveness and prevent the agent from “wandering off”.
For an agent to be effective, it must have authority, which makes the agent more difficult to secure. This is called the agent paradox. The default pattern in good agent design is to DENY permissions, and ALLOW only as a thoughtful, secured choice.
Human Analogies for Open Source, Accelerated Computing, and the Edge
You can think of a human as a closed source model. We are opaque by default. I perceive a set of inputs and take an action as a result. Even if I explain how I did it, the true technical mechanisms are largely closed to other humans. Even a neurologist only has a very selective view into the complex organic relationships that make human agency possible.
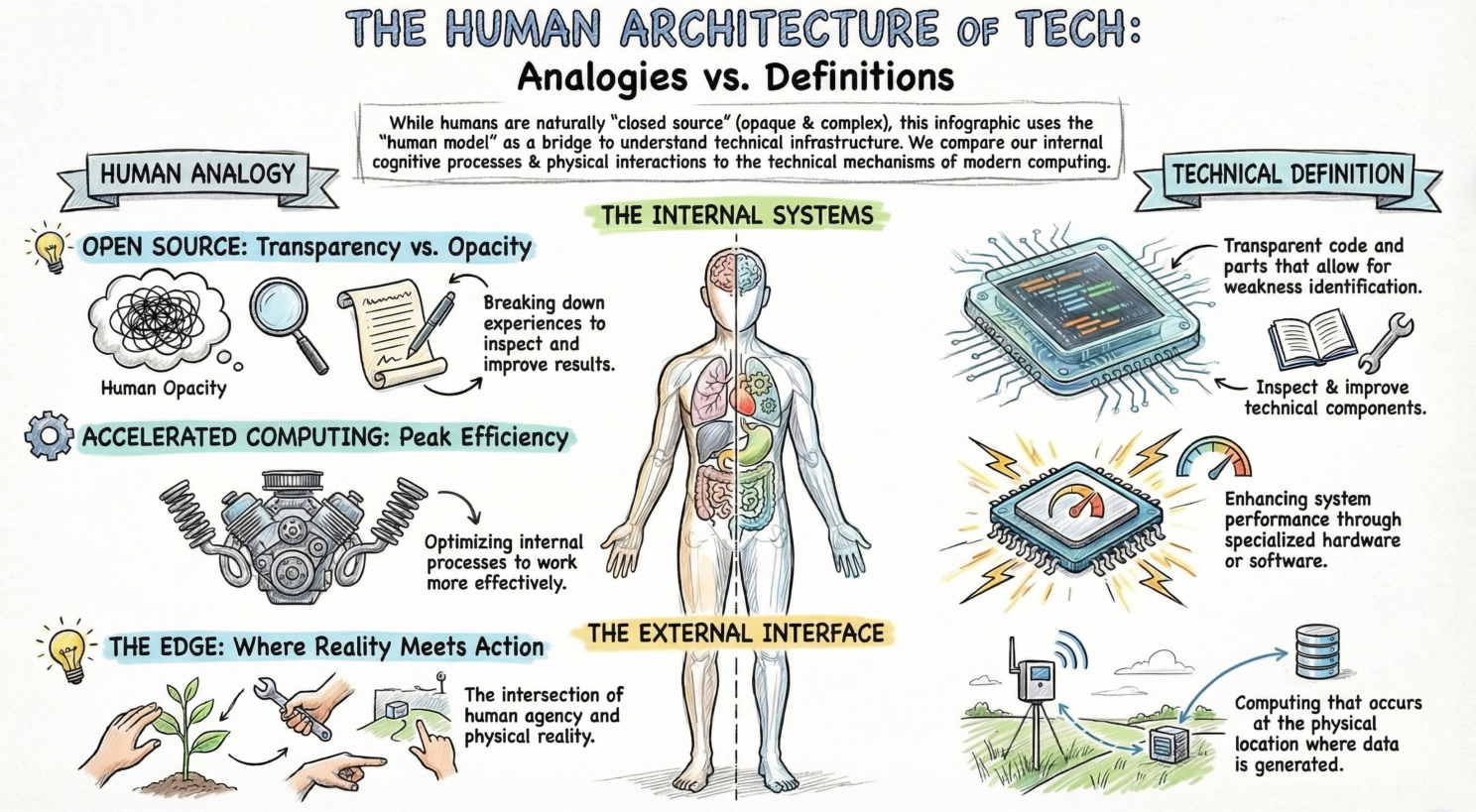
But what if our inner world was transparent? What if we could break ourselves down and inspect the way we do things? What if we could look at all the experiences we had over a lifetime that caused us to make a particular decision? What if we could double click on each other? Think of that as open source. If we could understand the pieces and parts, we could identify weaknesses, improve results, remove bottlenecks. We could make systems work more effectively, faster. Think of that as accelerated computing. And if we could do that not just with internal processes, but within the context of physical reality, we could also impact the world. You can think of that as “the edge” – that place in human reality that intersects with physical reality. (I'm definitely not saying I would want open source people, by the way. Just trying to create an analogy).
Open Source Model Development
I had not realized that NVIDIA was in the model making business. NVIDIA Nemotron is a family of open-source, foundation models and datasets designed to build and deploy agentic AI systems. Now that we understand how open source allows us to better understand and optimize how things work, we can start to see why NVIDIA might want to build models and expose them to others.
Building models allows them to anticipate what their clients will need by experiencing those needs firsthand. Designing, pre-training, training, post-training, deploying, and supporting a family of models requires a kind of learning that can only be gained by doing. It required NVIDIA to become experts at what is needed to design the requisite AI infrastructure and to accelerate the ecosystem around that infrastructure. Knowing what to build and having a perspective on what needs to be built. Frankly, this is one of the many reasons we build products at PhoenixTeam, and why I spend weekends and early hours tinkering.
Making models open source invites others into the process who likely see things differently and can make different contributions to the process. The OpenClaw moment was a shining example of the impact a small, community project can have. It showed us how one small project can create a robust and diverse ecosystem (that requires NVIDIA solutions, of course). Hence the rationale for making open source models.
What is the significance of data in this equation, and the fact that NVIDIA released the data? They found that 75% of the compute required during the process are actual required in synthetic test data degeneration and running experiments. Remember, we are running out of data and data scarcity of training is a big deal.

There are four basic stages to training a generative model, and Nemotron as a family of models is really an approach. In addition to models, NVIDIA has also released the training and fine tuning data and the techniques. This goes with the model family. This model family includes everything you need to design and deploy agents, most of which can run locally if wish (except the largest model in the family, which is 253B parameters and is too big to run on a DGX Spark). But it also has smaller, specialized models for reasoning, speech, and rag. I think my new DGX Spark comes Nemotron ready.
Accelerated computing is this idea that you can take certain parts of a system workload and offload them to accelerated processing that uses a different type of processor (the GPU – graphic processing unit). Accelerated computing speeds up the right workloads enormously, but if you apply it to the wrong things, it can slow most things down. That is why Jensen talks so much about identifying the parts of the stack that are truly “accelerable” instead of assuming every workload belongs on a GPU. Wasted effort makes AI that is dumber. Think of accelerated computing as steps in a chain, and the goal is to accelerate as many of those steps as possible. So, the data set used for training is a link in the chain of acceleration.
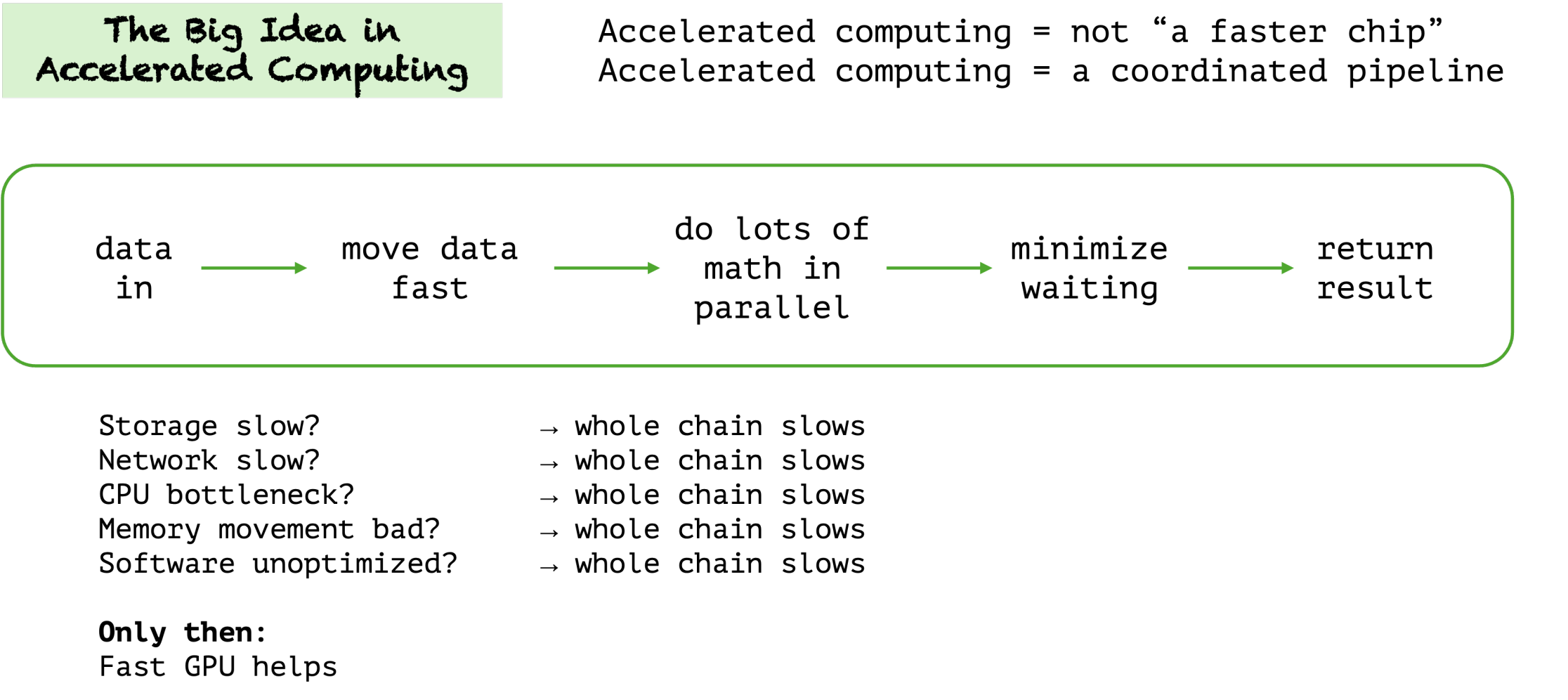
Accelerated computing slows most things down. This really resonates with me. The solution to all problems is not a large language model. Every problem doesn’t need an agent. Accelerated computing has a point of view, focus, and specialization. So the idea is to identify what computations in the future will be important and can/should be accelerated. Think beyond the GPU and stick with first principles. Preach!
You can design for acceleration, which is what they did with Nemotron. It was one of the up front design principles. Nemotron was also designed for mixture of experts (MOE) from the beginning and designed to deal with “numerics” and “sparsity”. To be designed for numerics means NVIDIA designed Nemotron so it works well with the messy realities of GPU math, not just idealized floating-point math on paper. To be designed for sparsity means the models are structured so that only the needed parts fire, and the system is built to make that selective firing efficient instead of wasteful.
In a model that is more closed, you can really only alter the behavior through prompt engineering and model fine tuning (and whatever other capabilities the model provider shooses to allow you to have). There can be very inefficient parts of the model, it's processes, or its data that simply cannot be altered. Accelerated computing is about making the chain go faster, if parts of the chain are hidden then you lose that opportunity for acceleration.
I never really understood what the edge even was until last year. And I really didn't get the socalled "internet of things (IoT)". The edge is where digital meets our world. A scanner in a grocery store. A sensor on a shelf in a warehouse. To put generative capabilities on "the edge" is to deploy models that are small enough to be practical and also smart enough to be worth it. That's a serious engineering problem.
This is what makes my new DGX Spark so exciting. Some of you will remember my journey to deploy a 70 billion parameter model on my massive Mac pro. I tried to run a bigger one but my machine did not have sufficient compute. DGX Spark is a small desktop AI computer from where you can run, test, and fine-tune large AI models locally. It’s basically a very powerful “AI box for your desk,” built specifically for AI workloads rather than general-purpose computing. And the best part is you can air gap it. I picked one up at the NVIDIA swag store for an amount I will only tell you if you ask me directly. I can say it's fully five times less expensive than my Mac pro.

I also learned about something I want to look into for our commercial product, which is Llama Nemotron Nano VL. I had to do a bit of research on this, but they described it as a “tiny open VLM that rivals closed models in doc extraction” (VLM is vision language model). I want to try this one out for sure.
Open source at the edge means more opportunity to accelerate. Given that the edge requires seriously compact and optimized solution, you can see that being able to engineer the inner parts of the model could be the difference that's needed to make edge computing feasible.
Open Source as Component of Mixture of Expert (MOE) Architecture
Model selection is not an “or” but an “and”. It’s not open or closed, this model or the other, it’s open AND closed, this model AND these other models. We are creating or at least using systems of models. When you use any of the (closed) foundation models, you are really using multiple models to do different things – that complexity, however, is abstracted from that interaction. That is part of the value of working with a closed foundation model.
However, it’s not one size fits all. More and more (I’d say approaching table stakes), we are seeing “mixture of experts (MOE)” approaches where we use different models to do different things, in the same overall system. Maybe a VLM for document analysis, Claude for general knowledge, and a domain specific model to solve a particular type of problem. We are seeing more and more usefulness of this model when we have specialized AI solutions (i.e. a general model isn’t the best) or when we are looking for efficiency (again, a general model is not terrifically efficient).
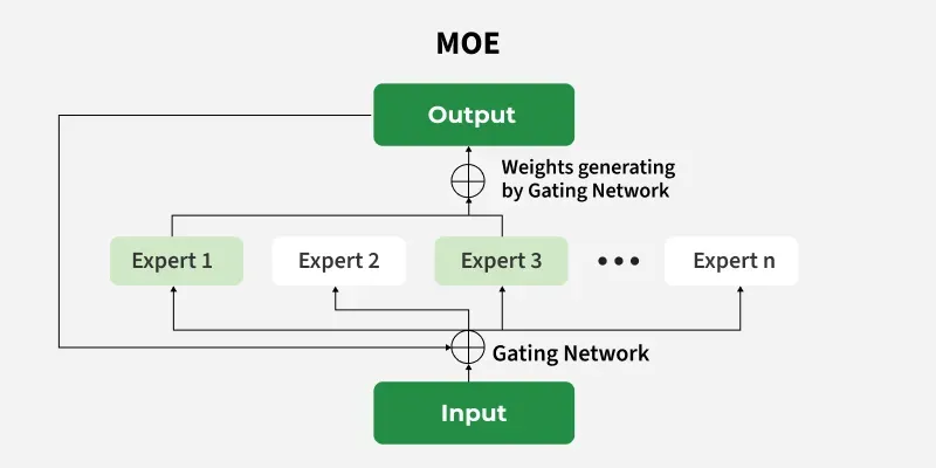
About the data – the most valuable data in an organization ALWAYS has the most restrictions. And the argument for open here is that we need more diversity to optimize for unique and specialized data and domain needs. We simply may not trust a closed model whose inner working we do not understand, whose training data we have no visibility into, to handle our most valuable data.
Nemotron Performance Engineering

For the more technical of you readers, Nemotron is a pretty solid model family according to all the benchmarks, how this was achieved:
It’s fastest on PinchBench and has frontier level accuracy. PinchBench is a benchmark for testing how well language models perform as OpenClaw agents. Seems worth trying out for me. DGX Spark here I come.
By Tela Mathias, CTO at PhoenixTeam




